
EfficientDet — A Comprehensive Review
There are extensive research and development is going on especially in the field of object detection and recognition. Each day various models and algorithms are invented to solve the problem of accurate object detection.
Google brain team has recently published object detection paper in CVPR 2020 which is based on EfficientNet. It achieved a state of the art accuracy among the current object detection methods. This article will help you to understand the building blocks of EfficientDet.
Table of Content
- Introduction
- Proposed Algorithm
- Results/Comparison
- Conclusion
- References
Introduction
The proposed method includes several optimizations to improve efficiency. In real-time applications such as edge systems, the major constraint is the limited computational resource. Unfortunately, many current high-accuracy detectors do not fit these constraints. We need to find a perfect balance between high accuracy and supported computational power. EfficientDet is designed in such a way that is highly accurate and can be adaptive to a wide range of resource constraints.
There are two main features we need to know thoroughly to understand the paper. In this blog, we will get brief information about compound scaling and BiFPN.
Proposed Algorithm:

EfficientDet Model architecture
EfficientDet uses ImageNet pre-trained EfficientNet architecture as a backbone. The proposed BiFPN serves as the feature network, which takes level 3–7 features P3, P4, P5, P6, P7, from the backbone network and repeatedly applies top-down and bottom-up bidirectional feature fusion. These fused features are fed to a class and box network to produce object class and bounding box predictions respectively. The class and box network weights are shared across all levels of features.
Compound Scaling
Let’s say we want to increase the accuracy and efficiency of our network. The solution can be to use a large input resolution or to use deeper layers. Now we have to try all these methods which can be a cumbersome process. But, what if we merge all these scaling methods into one. That’s the key idea of compound scaling.

Comparison of different scaling methods. Unlike conventional scaling methods (b)-(d) that arbitrary scale a single dimension of the network, compound scaling method uniformly scales up all dimensions in a principled way.
Compound scaling was introduced in EfficientNet paper and a game-changer for model scaling methods. The first step in the compound scaling method is to perform a grid search to find the relationship between different scaling dimensions of the baseline network under a fixed resource constraint. This determines the appropriate scaling coefficient for each of the dimensions mentioned above.
This compound scaling method consistently improves model accuracy and efficiency for scaling up existing models such as MobileNet (+1.4% imagenet accuracy), and ResNet (+0.7%), compared to conventional scaling methods.
BiFPN
First of all, we need to understand what exactly is FPN(Feature Pyramid Network). I recommend going through the understanding of FPN to get the main idea. The aim of BiFPN is to effectively aggregate multi-scale features in a top-down manner.
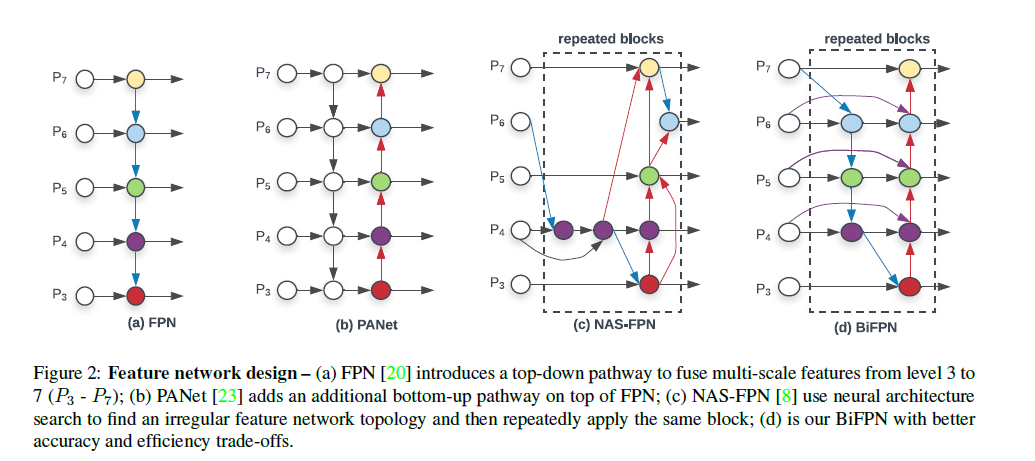
In the conventional FPN approach(above figure(a)) It takes level 3–7 input features, where P represents a feature level with a resolution of 1/ (2^i) of the input resolution image. For instance, if input resolution is 640x640, then P3 represents feature level 3 80x80 resolution While P7 is 5x5. The conventional FPN aggregates multi-scale features in a top-down manner. While BiFPN uses both bottom-up first and then top-down approach to get the better accuracy trade-off.
To improve model efficiency, this paper proposes several optimization techniques for cross-scale connections. They treat each bidirectional (top-down & bottom-up) path as one feature network layer and repeat the same layer multiple times to enable more high-level feature fusion. Weighted Feature Fusion technique is used to club different levels of the feature as different level of resolution contributes differently.
Results/ Comparison:
EfficientDet is evaluated on COCO 2017 detection dataset. There are a family of EfficientDet network D0-D7 (based on the #depth of layers) which are evaluated on COCO results.

As per the above results, we can say that the EfficientDet-D0 model achieves similar accuracy as YOLOv3 with 28x fewer FLOPS. While comping with RetinaNet and Mask-RCNN, EfficientDet-D1 achieves similar accuracy with up to 8x fewer parameters and 25x fewer FLOPS. EffiecientDet-D7 achieves 52.2 mAp which is the state of the art results for detection algorithms.
Conclusion:
In this blog, we studied network architecture and basic design implementation of EfficientDet in order to improve accuracy and efficiency. EfficientDet achieves state-of-the-art accuracy with much fewer parameters and FLOPs than previous object detection and semantic segmentation models.
This was the short overview of EfficientDet but still, to get the better understanding about Weighted Feature Fusion and compound scaling, these are the other references which you can always look up to.